从一个Emoji字符说起
一、前言
在和朋友聊天时,突然无话可说,屏幕前的你该如何是好呢? 很多时候屏幕前的我们,都会想到发个表情,然后彼此心照不宣地沉默。如果你用的是windows 10的新版本,按下 winkey + period (即windows图标和英文句点按钮),就会有如下的弹出框。
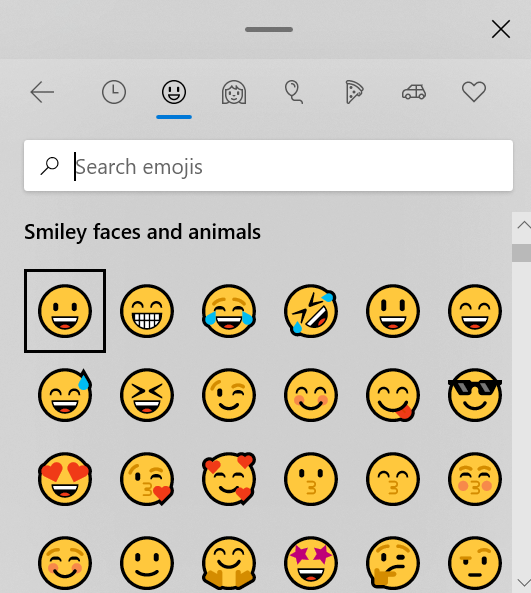
图1.1
反复斟酌、几度纠结之后,你选择了这样一个表情:😤。将鼠标停留在这个表情上几秒,可以看到提示文字:“傲慢”。如果你用的是andriod、ios,在输入法中仔细搜寻,一定也可以发现这样一个表情。
如果哪里都找不到,也没关系,直接将这个表情复制,粘贴到微信聊天框中,回车,成功地将这个表情发了出去。在对方沉默不语的时间里,你点开了微信对话框里的表情,却发现怎么也找不着这个傲慢的表情?!但是这个表情的确正确地显示了呀?这是怎么回事呢?“微信连不存在的表情都支持,太厉害了叭!”也许你会发出这样的感慨。也有可能你会嗤之以鼻:“不过是显示了一张图片而已”。不过,这真的是图片吗? 且听我缓缓道来。
二、Emoji的前世今生
上面的表情,其实是个emoji字符。emoji这个词,互联网时代的人当然都不会陌生。但是刚刚的表述,又说它是表情,又说它是字符,似乎将表情和字符混为一谈了,这是怎么回事呢?其实准确来说,emoji应该称为“表情字符”,其本质还是一个字符,只是个用来象征表情的字符罢了。一个emoji字符,和一个字母、一个汉字,没有什么本质的不同,或者想象一下,对于一个不懂汉字的人来说,汉字看起来也许也就像一个个表情呢~ 当然啦,表情也可以用图片表示,至于计算机上区别字符和图片的根本因素是什么,稍后再论,这里先说下emoji出现的历史。
Emoji用日语表示就是「絵文字」,平假名为「えもじ」,1999年,由株式会社NTT DoCoMo的iMode服务团队开发,在12×12格的方格纸上以简单的图案描绘出人的各种表情及生活事物,再把它们对应成字符数据,NTT公司的这一发明意在提供一种在画面尺寸和通信量受限的情况下,让用户们通过视觉顺利进行交流的方式。
Emoji诞生之初,就得到了年轻人的追捧,到了2004年左右它已经被全日本所接受。2009年emoji被收录进Unicode编码,成为了世界标准的通用字符,2012年智能手机中加入了对emoji的支持,2014年提出了“世界Emoji日(World Emoji Day)”,2015年《牛津词典》的年度词汇是😂,2016年起,纽约现代美术馆(MoMA)将NTT DoCoMo的iMode中提供的第一版176个emoji纳入永久收藏。如今,emoji已经成为了iOS、Android、Mac OS及Windows中默认支持的表情符号。
关于世界Emoji日,是在每年的7月17日,因为提出了World Emoji Day, 因此各个平台上表示日历的Emoji也都展示的是7月17日,📅Calendar Emoji,还有一个专门的World Emoji Day网站:点我试试
iMode的开发负责人是栗田穣崇(Shigetaka Kurita),也是他设计了最早版本的emoji,引用一句栗田先生后来的回忆分析:
“在以数字信息互动为主的手机世界中,仅用文字来沟通的话,容易产生理解上的误会,因此有必要附加上感情语气,因此emoji的登场有其符合时代刚需的必然性”

图2.1
一个没有接触过编程的人,应该也能看懂上面大部分的内容,唯一可能有疑惑的大概是: 2009年emoji被收录进Unicode编码。这个Unicode编码又是个什么玩意呢? 开头说的计算机上区别字符和图片的根本因素是什么呢?
三、字符集和字符编码
说起字符集,首先不得不扯一些语言学和计算机的基础。
3.1 语言学简介
每个文化都有自己的语言体系,每种语言大致都会包含 发音系统、书写系统、语法系统 等几大方面。发音系统的基本单位是音素(phoneme),书写系统的基本单位是字素(grapheme),语法系统的基本单位是语素(morpheme)。
- 小学时,我们学的声母表、韵母表,里面的每个音,就可以认为是普通话的音素,英文的音标就可以当作是英文的音素。
- 中文的字素有两种看法了,一种认为汉字可以按照偏旁部首的拆分,每个偏旁部首作为一个字素,比如“河”,可以认为是“氵”和“可”两个字素(李玲璞先生就持这种看法),另一种看法则认为每个汉字作为一个字素。而在英文等拉丁语族中, 字素其实并没有特别确切的概念, 不同的论文中可能使用的是不同的概念.
- 中文的语素通常就是对应着单个汉字,而英文的语素可能就会复杂点,例如really, 可以看作是 real 和 -ly 两个语素,这种区别主要是因为中文不通过词语形变来表达语法,只通过语法词汇来区分语法,比如“的”、“了”等。
当然啦,回到字符集上来,这里面与字符集关系最密切的显然是字素,那么文字、字符、字素,这些有区别吗?为什么要发明这么多名词?!太难了…
1)先说“文字”
文字是记录语言的视觉符号系统,是人类社会运用语言相当长时间以后出现的文化现象。
也就是说,文字是个宏观的概念。语言的发展都是先有发音后有文字的,文字的出现是一种必然,同样作为信息的载体,文字显然比声音更容易保存,这也是为什么历史上知识都是通过文字流传下来的。即使是互联网时代来临,多媒体技术诞生,文字载体相对于音频载体,信息密度也是高到不知道哪里去了,音视频种的信息冗余太大,利于传播,但并不利于保存,如今一门语言如果没有文字,慢慢也就会被淘汰了吧。
2)再说“字符”(Character)
字符这个概念在英语和汉语种很容易,一个字母、一个汉字就是一个字符,如果给个概念,大概是:拥有实际语义的最小文字单位。但这其实并不严谨,还引入了更为模糊的语义概念。我觉得,简单一点可以理解成,字符就是一门语言的文字中,可以独立有意义的最小单位,它并不是一个特别严谨的概念。只是在计算机科学中,字符的概念有特殊的地位,接着往下看, 暂且按下不表。
3)后说“字素”(Grapheme)
正如前面所述, 中文的字素概念有两种学派, 拉丁语族的字素也分类不明确, 所以实际上, 很难严格意义上给字素一个具体的概念进行分类. 只能模糊地给出“字素是书写系统的最小功能单位”, 但是具体这个单位该细分到什么程度, 标准并不统一. 那为何还需要提到这个概念, 一切都是因为, 和字符一样, 在计算机科学中, 字素这个概念被赋予了特殊的意义, 而具体意义是什么, 一直往下看, 你就可以看到.
后续行文中, 在未涉及到字素概念前, 可以暂且先认为一个字符就是一个英文字符、一个汉字、一个符号
3.2 计算机科学简介
学过编程的人都知道,计算机程序中,一切数据的最终形态,其实都是二进制。

图3.1
也就是说,此时此刻呈现在你眼前的所有信息,你耳中听到的音乐,在计算机中全都是 010101010101 这样的存在。
世界上有10种人,懂10进制的,和不懂10进制的。——鲁迅
那么文字自然也是如此,每个有独立语言的国家,在计算机诞生之初,便需要考虑如何表示和存储字符了。即如何将本国语言中的每个文字,对应到一个二进制数中,而这种一一对应的规则,我们就可以将其称为字符集。
在计算机世界中,二进制虽然可以区分到每一位,但实际的读取和写入,最小都是1个字节(byte),1个字节包含8位二进制。
3.3 (编码)字符集
在说字符集之前,先厘清几个概念。 而这些概念中,我们经常将编码字符集和字符集混为一谈,倒也不太影响理解,因此这里也就不那么严谨,理解万岁!!
- 字符集/字符库(Character set/Character repertoire):被一种或多种语言使用的字符的集合。也就是说,字符集告诉了我们,一门语言中,到底有多少个字符,每个字符是什么。
- 编码字符集(Coded character set):每个字符对应一个独一无二的数字的集合。即将字符集和数字一一对应的集合。
- 码点(Code point):编码字符集中的任一个合法数字,称之为码点。
- 编码空间(Code space):包含所有码点的整数范围。
- 编码单位(Code unit):用来编码字符集中每个字符的二进制序列。
对于计算机的诞生国美国来说,很简单,只需要考虑26个英文字母及其大小写,再加上阿拉伯数字、标点符号和一些特殊的控制字符,字符集的容量只要128够了。因此美帝标准协会制定了一个标准,用来表示英文世界中需要用到的所有字符,这个标准就是ASCII(American Standard Code for Information Interchange)。128个数,用二进制来表示,7位也就够了,一个字节绰绰有余。
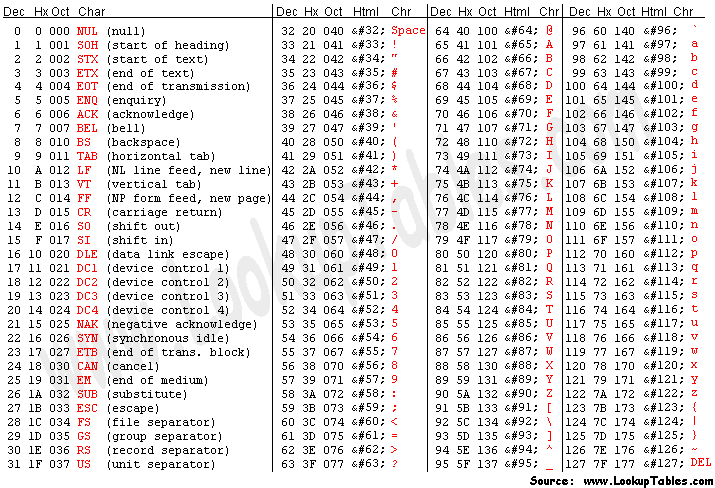
图3.2
但是渐渐地,欧洲国家也开始有了计算机,它们使用更多的字符,因此将一个字节中没有使用的最高位也用上了,制定了一套Extended ASCII Codes.
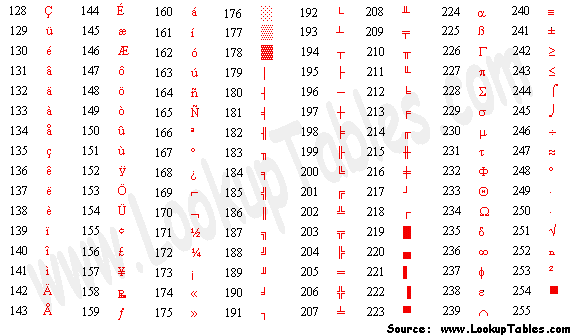
图3.3
后来亚洲国家也开始使用计算机,汉字需要制定一套标准字符集,因此中国国家标准总局逐步制定了GB2312、GBK、GB13000、GB18030的标准字符集。日语也需要一套字符集,于是日本政府就逐步制定了JIS X 0201–1976、JIS X 0208–1990、JIS X 0212–1990、JIS X 0213–2000等标准字符集。
这样一直下去,问题就来了,不同国家之间没有沟通,同样一个数字,用汉语的编码字符集解读是正常的,用日语编码字符集就会出错。为了解决这个问题,各国之间也想约定一个世界统一的文字字符集标准,这就诞生了 Unicode。
Unicode目前使用了0(0x0000)1114111(0x10FFFF)的编码范围,也就是说,当前Unicode的编码空间(Code Space)是00x10FFFF,之所以说是“当前”,是因为Unicode本身也是在不断发展的,早期Unicode的Code Space只用了0~65535(0xFFFF)的范围,只是随着发展,Unicode标准委员会的人才发现,原来还有各种各样隐藏在世界各处的字符,当然需要加进来!这就导致BMP的范围不够用了,只好扩展Unicode的范围,只是,实际扩展到1114111(0x10FFFF)之后,委员会的人又发现,这么多字符不可能用得完呀!不用又觉得浪费,不如加一些不太正常的语言文字吧,这就包含了文章开头提到的Emoji表情字符。
Unicode范围如此之大,当然就会想要将它划分成几大块,方便分类,也更容易理解,Unicode标准将这种分片叫做平面(Plane)。最早使用的 0~0xFFFF,就是 基本多语言平面(BMP, Basic Multilingual Plane) 的范围。
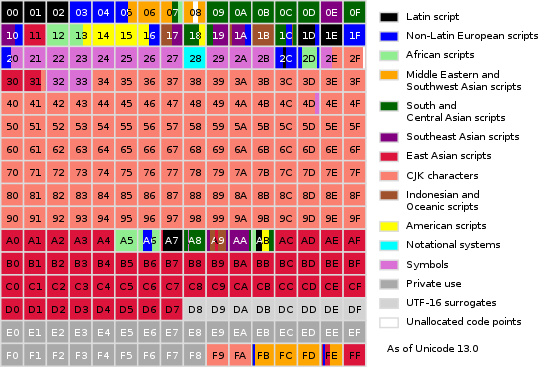
图3.4
Unicode总共划分了17个平面,每个平面65536个编码空间,总共正好是 65536*17=1114112=0x10FFFF+1
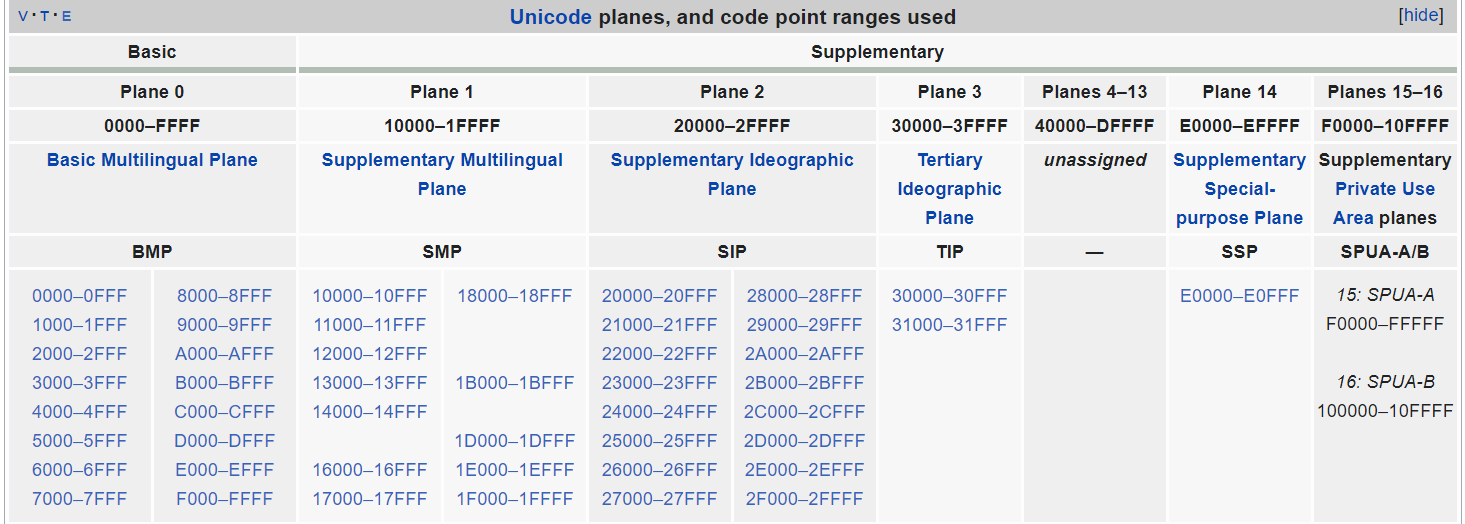
图3.5
所有的Unicode字符都可以在 这里 看到。 值得注意的是,哪怕Unicode的编码空间大到用不完,却也不包含任何商标,比如Windows和Apple的注册商标等,这也是为何 文章开头只能用 winkey 来指代windows的按钮,却无法找到合适的字符。
3.4 字符编码
Unicode字符集,在概念上只是编码字符集,它本身只指定了每个数字对应哪个字符,但在计算机中,这个数字究竟存储成什么样的二进制,却没有指定一个统一的标准。Unicode字符集的字符编码方式,就是UTF(Unicode Transformation Format)系列。
3.4.1 UTF-32
UTF-32就是用32位(也就是4个字节)来存储一个Unicode字符集中的一个字符,UTF-32的值,正好对应Unicode字符集中字符的码点(Code point)值。
比如:
- 😤的码点值为
128548(0x1F624),那么对应的UTF-32编码也就是0x1F624,在计算机中存储的二进制形态就是:00000000 00000001 11110110 00100100 - “梦”的码点值是
0x68A6,用UTF-32存储在计算机中就是:00000000 00000000 01101000 10100110 - “S”的码点是
0x0053,用UTF-32存储就是:00000000 00000000 00000000 01010011
UTF-32编码在实际中是没有被使用的
3.4.2 UTF-16
相信你已经发现UTF-32的问题所在了,那就是大多数字符都不需要用到32位,最多也就是24位(3个字节),所有字符都用UTF-32编码太浪费,而且Unicode标准刚制定时,也就只有BMP范围,BMP范围的字符,两个字节就刚好够了,因此有UTF-16的编码格式。在BMP平面上的字符,其UTF-16的编码,和UTF-32一样,也就是字符对应的码点值。
比如:
- “梦”的码点值是
0x68A6,用UTF-16存储就是:01101000 10100110 - “S”的码点是
0x0053,用UTF-16存储就是:00000000 01010011
但是这样就出现了一个问题,那些后来追加的字符集,码点值大于 0xFFFF 的,该怎么用 UTF-16 表示呢? 比如😤。而且这种表示方法,还不能影响已有的UTF-16编码的字符数据,这可怎么办?
没办法,为了照顾很多采用UTF-16的系统、软件,Unicode规定了BMP平面中的 0xD800~0xDFFF 为 surrogates 字符,在图3.5中也可以看到,Unicode规定这部分码点值,不能用来表示任何字符。实际上,这部分还可被分为两部分,0xD800~0xDBFF,称为 high surrogates,0xDC00~0xDFFF,称为 low surrogates。
这样的话,对于一个大于0xFFFF的值,如果想用UTF-16编码,就可以用32位4个字节表示,high surrogate + low surrogate 拼成一个surrogate pair就行,这样在程序读到两个字节时,如果判断它是 surrogate,那么就认为它不是正常字符,需要和另一个surrogate拼接起来才行,组成另一个字符。例如:
- 😤的码点值为
0x1F624,那么对应的UTF-16的surrogate pair也就是0xD83D + 0xDE24,二进制就是:11011000 01011101 11011110 00100100
不难算出,Surrogate pair总共能表示 1024*1024=1048576=0x100000个字符,所以UTF-16总共可以编码0x100000+0xFFFF=0x10FFFF个字符,这也是为什么当前Unicode字符集的上限是这么大的原因,也影响了接下来我们要说的UTF-8的上限范围。
3.4.3 UTF-8
更进一步,对于英语国家的人来说,总觉得一个字节八位就足够了呀,用两位也觉得浪费空间,但对于其他国家比如中国来说,一个字节又肯定不够,这便引出了一种变长的编码格式UTF-8。引一张Wiki上的图来说明UTF-8的编码规范。

图3.6
例如:
- “S”的码点是
0x0053,用UTF-8存储就是:01010011 - “µ”的码点是
0x00B5, 用UTF-8存储就是:11000010 10110101 - “梦”的码点值是
0x68A6,用UTF-8存储就是:11100110 10100010 1010 0110 - 😤的码点值为
0x1F624,用UTF-8存储就是:11110000 10011111 10011000 10100100
如果我们算一下四字节的UTF-8实际能表示的范围,会发现理论上应该能表示到 0x1FFFFF ,但是实际上却限制了上限为 0x10FFFF ,这就是上节所述的UTF-16的上限,既然编码空间足够大,目前看来总是够用的,那为了兼容UTF-16,就先这样规定吧。(RFC3629的标准如此规定了上限,大概就是这样想的吧)。
关于UTF-8,还有一些比较有意思的现象,比如在早期Windows中, 当你在 windows 的记事本里新建一个文件,输入”联通”两个字之后,保存,关闭,然后再次打开,你会发现这两个字已经消失了,代之的是几个乱码 ,这是由于GBK编码和UTF-8编码的识别错误导致的,可以动手搜一搜相应字节码分析一下,然后再看[17]这篇文章,验证下自己的分析是否正确。
3.5 大端小端
Danny Cohen在论文 [13] 中提出了大端小端的说法,想要结束字节序(Endianness)的“战争”,自那以后,在程序员眼中,大端小端不再是《格列佛游记》的名词,而是字节序的专属名词了。在介绍UTF-32、UTF-16、UTF-8三种编码方式时,我们都没有考虑大端小端的问题,细心的读者可能已经意识到这个问题了,在此我们再简单介绍下。
大端(Big Endian): 将一个多位数的高位放在较小的地址处,低位放在较大的地址处
小端(Little Endian): 将一个多位数的低位放在较小的地址处,高位放在较大的地址处
直接拿Wiki上的示例说明, 0x0A0B0C0D 这个32位的整数,大小端分别如下:
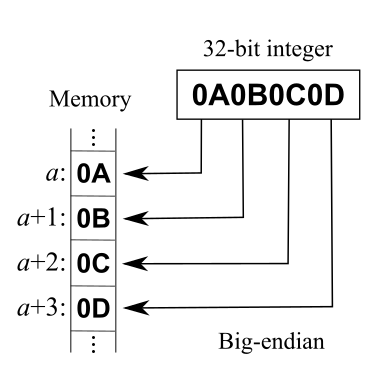
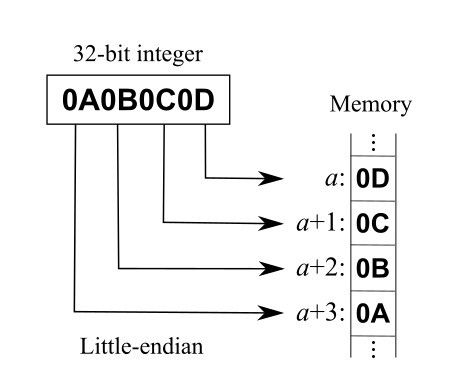
图3.7
我们还是以😤为例,在UTF-32中编码为: 0x0001F624,大端小端分别如图。
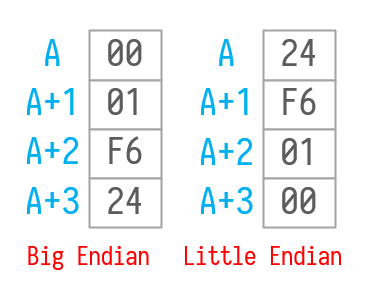
图3.8
在UTF-16中编码为: 0xD83DDE24 ,大端小端分别如图。
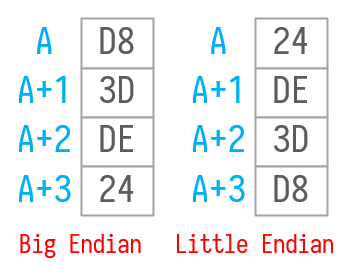
图3.9
看到这里,屏幕前的你,是不是都自信满满地准备自己画出UTF-8的大端小端了? 不过对不起,UTF-8是不需要区分大端小端的。倒回去看UTF-8的编码标准,我们会发现,UTF-8的最小处理单位是单字节,而不是像UTF-16和UTF-32的多字节。也就是说:
- 对于UTF-32,程序需要一次读取4个字节,然后计算这四个字节的实际值,如果字节序不同,会导致结果不同
- 对于UTF-16,程序需要一次读取2个字节,然后计算这两个字节的实际值,如果字节序不同,结果也会不同
- 但是对于UTF-8来说,程序一次只会读取1个字节,程序需要通过每个字节的字节头去决定是否需要继续读取下一个字节,既然一次只读取一个字节,自然不会受大小端的影响。
😤用UTF-8编码是 0xF09F98A4,那么实际上,计算机永远会先读取 F0 ,然后判断还需要读取接下来的三个字节,就依次读取 9F 、98 、 A4,然后将四个字节组合计算得出实际表示的值。计算机总共读取了四次,而不是一次读取了 4个字节。实际在计算机内存中,存储总是如图。
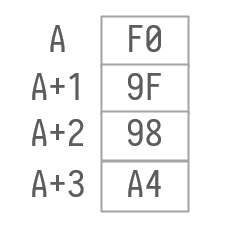
图3.10
3.6 BOM(byte order mark)
既然字节序对计算机读取字符有很大的影响,那么对于一个文本文件,知道它实际存储的数据是大端还是小端就很重要了。为了实现这个目的,使用BOM来标记一个文本文件的开头,从而区分该文件是大端还是小端存储的。BOM本质上也还是个字符,只不过是个特殊的字符,在UTF-16的文本文件中,BOM就是 0xFEFF ,这时,计算机程序首先读取文本文件的前两个字节,通过判断高低地址的实际值,就可以判断是大端还是小端了。 0xFEFF这个字符实际上被称为ZERO WIDTH NO-BREAK SPACE字符,之所以用这个字符,是因为根据UTF-8编码标准,UTF-8不可能出现0xFE或者0xFF开头的字符,因此不会和UTF-8产生混淆。
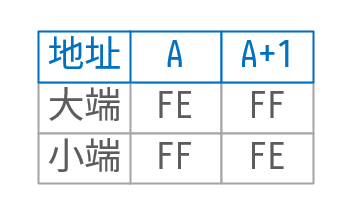
图3.11
对于UTF-32来说,虽然实际上没人用,但是字节序标准还是有的,用 0x0000FEFF 四个字节表示。
对于UTF-8来说,由于其自身的字节就有字节头标志,也不区分大小端,其实并不需要BOM,但是在早期Windows系统中,默认用记事本编辑时,用UTF-8保存也会默认加个BOM头,具体是 0xEFBBBF 。这时,实际上这个BOM并不是标志字节序的,而是标志编码方式,即该文件是用UTF-8编码的,仅此而已。
而这个BOM带来了各种巨坑的问题,不限于:
- gcc会报告源码文件开头有无法识别的字符
- Linux的shell脚本无法运行:
Shell: #!/bin/sh: No such file or directory- 早期一些比较坑的教程会教人用记事本学Java,然后用 javac 编译,这时会报“错误:非法字符:blablabla”,但是却不在教程中说明这一点。(之所以记得这件事,是因为直到研究生期间还有人问过这种问题…
- 其他一系列知名不知名软件读取配置文件的坑…
- …
但是,竟然还有反向操作的,举一个自己曾经遇到的坑,知名音乐播放软件Foobar 2000,在读取 .cue 文件时,必须是 UTF-8 With BOM,曾经强迫症把所有 .cue 文件改成了 UTF-8 Without BOM,结果Foobar 2000全部无法识别…
其他还有一些不常见的BOM如下。
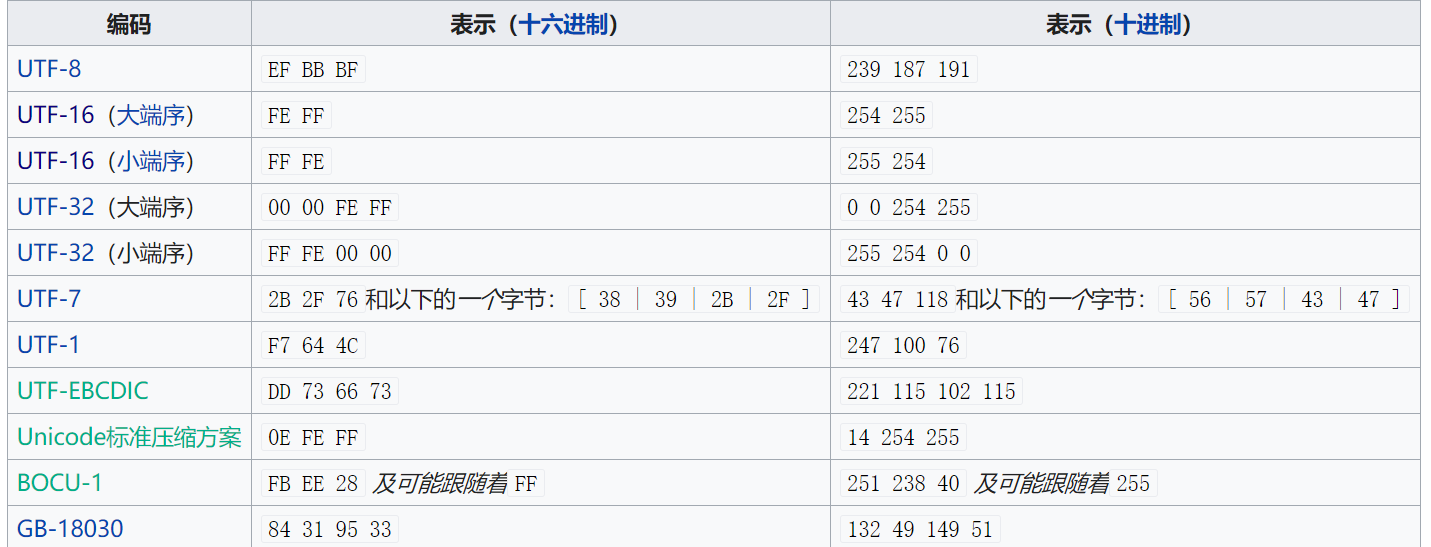
图3.12
3.7 Unicode控制字符
上面说到了UTF-16和UTF-32用 0xFEFF 作为BOM字符,这个字符实际上是不可见的,主要用于标志字节序。在编码字符集中, 这种特殊码位的字符,一般可以叫做“控制字符”(Control character,Non-printable character),即“用于控制文本解释或者显示,而不可见或不占空间的Unicode字符”。
而在Unicode的一般性分类中, 控制字符大多都归属于 Other(C) 这个大类. Other(C)大类下又分:
- Cc(Other, control), 共有65个, 而且这个数量永远都不会再变
- Cf(Other, format), 共有161个, 这是Unicode 13.0中的数量, 以后可能会再变
- Cs(Other, surrogate), 共有2048个, 永远都不会再变
- Co(Other, private use), 共有137468个, 永远都不会再变
- Cn(Other, not assigned), 还未分配的保留字符
这其中, 严格意义上来说, 只有Cc是控制类型的字符, 但是广义上或者口语化中所说的控制字符, 其实也包含了格式化类型的字符, 这就包括了Cf, 以及另一个和Other(C)平行的大类 Separator(Z)中的字符.
简单来说, 广义上将Control Type和Format Type的字符都作为控制字符来表达, 也没什么问题
对广义上的控制字符细分如下.
3.7.1 ISO 6429控制字符(C0与C1控制字符)
控制字符U+0000‐U+001F 与U+007F来自ASCII。此外,ISO 8859字符集定义了U+0080‐U+009F。二者都定义在ISO 6429中,常被称为C0与C1控制字符。
大部分这些字符在Unicode文本处理中没有明确作用。字符U+0000 <control-0000> ,NUL、U+0009 <control-0009> ,HT、U+000A <control-000A> ,LF、U+000D <control-000D> ,CR、U+0085 <control-0085> ,NEL常用于格式化字符。
这65个字符就是所有Cc类别的字符
3.7.2 Unicode引入的分隔符
为了简化几种换行字符,Unicode引入了它自己的分隔符来格式化文本:
- U+2028 line separator ,HTML:

,LSEP - U+2029 paragraph separator ,HTML:

,PSEP
这就是Separator(Z)大类中仅有的两个Format Type的字符了
因此, 剩下的所有细分类别, 其实全是Cf类别的字符, 包括了开始所说的0xFEFF
3.7.3 语言标记
不予叙述,可参考[18]的说明。
3.7.4 行间标注
3个格式化字符用于支持旁注标记(U+FFF9、U+FFFA、U+FFFB)。
所谓旁注标记(ruby character),又称注音标示、加注音、Ruby字符、ruby或rubi,是一种表意文字的音标印刷方式,广泛地运用于日文及中文。一般这些字是放于表意文字的上方或右边,作为文字的拼音或注解。
了解过HTML5的童鞋也许知道HTML5引入了 <ruby> 标签,也是同样的意思,(我之所以知道,是因为我的主页也用了嘛!~不过主页也是模仿前端大神的网页做的啦)

图3.13
3.7.5 双向文本控制
英文、中文的印刷作品,基本都是从左向右,自上而下的,但并不是所有语言的印刷品都是如此,比如日语就是自右向左的,中国古代的书籍也是。
Unicode本身是支持从左到右、从右到左,或者其混合排版,而不需要任何特殊字符。但考虑到为了处理一些特殊情形,Unicode还是定义了12个字符(U+061C、U+200E、U+200F、U+202A、U+202B、U+202C、U+202D、U+202E、U+2066、U+2067、U+2068、U+2069)以帮助控制嵌入式双向文本的顺序,最大可以有125层深。
这个到底是干嘛用的,主要还是因为世界上有阿拉伯语这种存在。。。
比如“阿拉伯字母”这五个字的阿拉伯语写法,就是:
أَبْجَدِيَّة عَرَبِيَّة
说实话我不知道屏幕前的你看到的实际上是什么样的字符串… 对照下图看看..
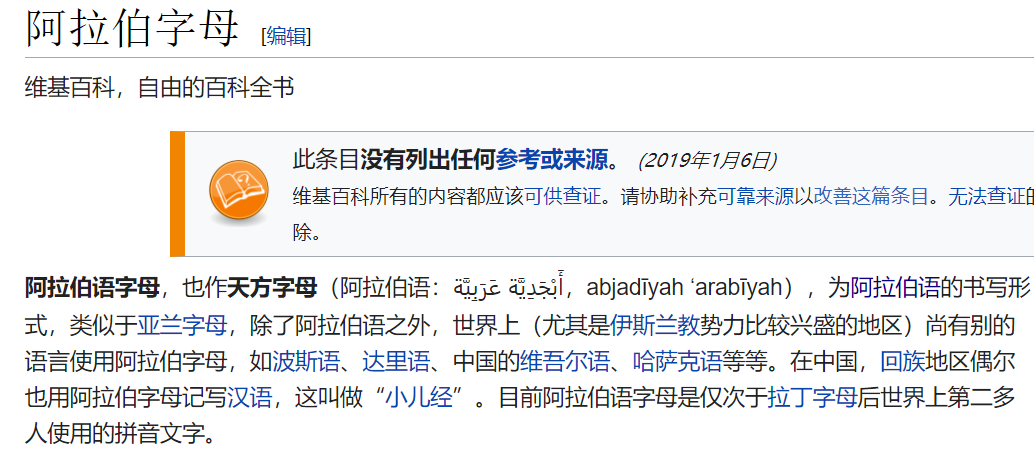
图3.14
而如果我在IDEA的编辑器中,赋值这行字符串为字面量,就会显示成下图,甚至影响了我的光标显示。。。

图3.15
这其中,虽然那个\u200E的 \ 已经位置错误,还是可以看出就是刚刚提到的Unicode定义的12个双向文本控制字符中的一个。实际上它的作用就是控制“从左至右书写标记”,而\u200F是“从右至左书写标记”
这就就是阿拉伯语的其中一个特殊之处:从右向左书写。(虽然日语、中国古籍,也都是从右向左,但只是排版概念上从右向左,而且还是竖着写的呀)。
阿拉伯语的这个特性带来了一个问题,如果在一行阿拉伯文字里,我写了一个英文单词,那该怎么办,nice 岂不是要显示成 ecin,于是就需要对一行文本内的某些文字再单独进行方向控制,那如果单词里再嵌套个阿拉伯字母呢,阿拉伯字母间再嵌套中文…… 如此套娃无穷尽也,因此Unicode规定了最大的嵌套深度是125层。
笔者按: 一个阿拉伯语撑起了字符串处理Bug的半边天…
3.7.6 异体字选择器
异体字的具体说明可参考[19]. 简单来说,就是一种语言中,某一个字有两种写法,但是意义完全相同,因此当初编码时,没有将其区分开,但在实际使用中,可能在用于人名等专有名词时,还是需要进行区分的,因此提供了“异体字选择器”这种控制字符。
3.7.7 控制字符的图片
不予叙述。
3.8 组合字符(Combining Character)
3.8.1 组合标记(Combining Marks)
上面在说控制字符时,有一类所谓的行间标记提到了“旁注标记”,在汉字上方标注拼音,可以称之为“旁注标记”。那对于某些欧洲语言来说,可以在字母上方加一些变音符号,实质上就表示成了另一个不同的字符,但它又是在原字符基础上变化的,如果每种变化都算作一个新字符,那即使是Unicode,可能也装不下这些排列组合的数量,因此出现了附加组合标记的组合字符。如Wiki的图[20]。
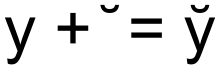
图3.16
在统一码中,用于欧洲语言和国际音标的组合用附加符号为〈U+0300–U+036F〉。上图的字符 y̌ 就可以表示成: \u0079\u030C , \u0079 就是 y , \u030C 就是变音符号’̌。
说到这里, 不得不提的就是在中二时期网络上流行的越界文字(Zalgo text), 其本质就是对组合字符的叠加, 因为Unicode没有规定组合字符必须是实际存在的字符, 那实际上我们可以叠加变音符号, 从而使得字符越界. 如果我们组合这样一个字符”\u0079\u030C\u030C\u030C\u030C\u030C\u030C\u030C”, 实际就是:
y̌̌̌̌̌̌̌
3.8.2 Grapheme 和 Grapheme Cluster
不过,你以为Unicode的组合字符序列到此就结束了吗? まだまだだね
关于组合字符序列, Unicode官网给出了一些FAQ[32]. 在这些Q&A中, 有一个问题:
Q: So is a combining character sequence the same as a “character”?
终于, 我们还是逃避不了这个问题, 究竟什么是字符? 组合字符还是传统意义上的”字符”吗? 怎么在概念上区分它们呢? 最终, 我们引入了字素(grapheme), 那个在语言学简介中提了之后, 一直没有出现的名词.
在程序员的眼中, 一个字符一般指一个Unicode的Code point, 但对于终端用户来说, 将字符等价于字素(grapheme), 是更加直观的, 字素的概念始终是不变的: a minimally distinctive unit of writing in the context of a particular writing system. 只不过之前无法具体细分字素的范围, 现在我们终于有工具能够确切描述字素的范围了.
在Unicode世界中, 一个字素至少包含一个Code point, 包含组合标记、控制字符等的多个组合字符序列也可作为一个字素. 这样, 至少在Unicode中, 我们将字素的最小范围限定到了一个Code point, 不会有比一个Code point范围更小的字素了!
事实上, Unicode引入的字素(grapheme)概念, 也可以称为用户感知字符(user-perceived character), 不仅可以在基础字符上附加组合字符, 用来形成新的字素, 也可以通过控制字符(如方向控制等)来形成新的字素.
字素的集合, 就可以统一称为 Grapheme Cluster, 或者通俗一点: user-perceived characters
So… Why? 为什么要划分这么细, 规定这么多细节, 直接认为 y̌ 就是两个字符, 不搞其他一些幺蛾子, 难道不香吗?
Unicode在TR29的技术报告里[30],给出了一段话:
Grapheme cluster boundaries are important for collation, regular expressions, UI interactions, segmentation for vertical text, identification of boundaries for first-letter styling, and counting “character” positions within text. Word boundaries, line boundaries, and sentence boundaries should not occur within a grapheme cluster: in other words, a grapheme cluster should be an atomic unit with respect to the process of determining these other boundaries.
我给大家画个重点,就是: grapheme cluster应该作为一个原子性的整体看待, 至少不能在在一个grapheme cluster中间出现换行符、单词分隔符、连字符等破坏性字符吧,那既然有这些限制,识别grapheme cluster的边界就十分有必要了, 这样才能更好的做字符排序、正则匹配、UI交互等字符串(实际上现在该叫字素串)处理工作
总结一下: 可以认为字素是在Code point/Character之上的一种更高一层的抽象.
在tr29中,还提到了三类不同的grapheme clusters: legacy grapheme clusters, extended grapheme clusters, tailored grapheme clusters. 具体的概念我也不翻译了,因为…水平不够. 就截几张图, 大概感受一下.
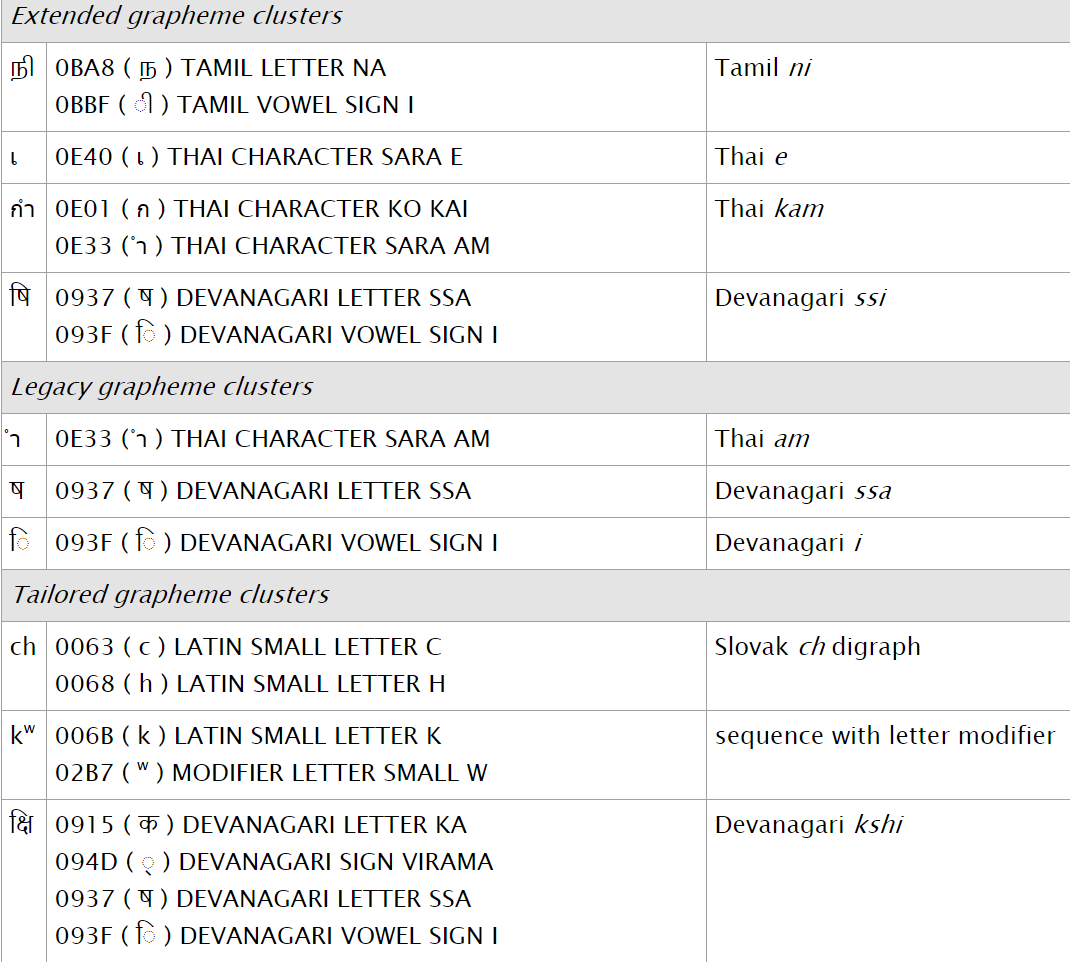
图3.17
好的,我知道其实你根本不想看,那就略过,我们继续。
3.8.3 Unicode等价(Unicode equivalence)及正规化(Normalization)
上面说完了字素, 又引入了另一个问题, 那就是:
带变音的拉丁字素等,使用广泛,以及占坑较早,因此,早早地就作为一个个的单独码点在Unicode种有一个码(keng)位了,而后来Unicode又规定了组合字符,这样,同一个字素就有可能有两种编码方式。比如“Å”,既可以是 \u00c5 ,也可以是 \u0041\u030A 表示,可以在这个网站 试试。这就引入了另一个话题,Unicode equivalence和Normalization,即判断两个字符/素串相等时,是否需要考虑这种等价情况,如果需要考虑这种意义上的等价,那么就需要对字符/素串先进行正规化(Normalization),再进行比较。
正规化即将彼此等价的序列转成同一列序, Unicode提供了两种等价概念:标准等价(canonically equivalent)和兼容等价(compatible). 两者的具体概念参考[22]. 标准等价的一个示例就是 Å
\u00c5和 Å\u0041\u030A, 兼容等价的一个示例就是 ff\ufb00和 ff\u0066\u0066
为了进行正规化, 自然会有两种想法:
- 一种是分解(Decomposition): 即将字素串中所有单个字素分解为等价的组合字符.
- 一种是组合(Composition): 即将字素串中所有分解后的组合重组为单个字素.
结合标准等价和兼容等价的概念, 正规形式自然可以分为四种:
| 正规形式 | 转换算法 |
|---|---|
| NFD,Normalization Form Canonical Decomposition | 以标准等价方式来分解 |
| NFC,Normalization Form Canonical Composition | 以标准等价方式来分解,然后以标准等价重组之 |
| NFKD,Normalization Form Compatibility Decomposition | 以兼容等价方式来分解 |
| NFKC,Normalization Form Compatibility Composition | 以兼容等价方式来分解,然后以标准等价重组之 |
好了, 等价就说到这. 以及, 后续我们还是使用字符串这个名词, 这一小段使用字素串, 主要是为了加深对字素的印象.
3.9 特殊的组合字符
在Unicode的兼容性等价示例中, 以 ff\ufb00 为例进行了说明. 这个字符和 两个f的组合 ff\u0066\u0066 具体是什么关系呢?
实际上\ufb00是一个连体字/合体字.
在西方字体排印学中将多于一个字母合成一个字形就是连体字, 经过演变、长时间流行后,一些连体字组合就直接变成了一个单个字符, 拥有自己独立的形式了.
说到连字, 其实和排版系统有所牵连, 就不细述概念了, 举个例子.
在VS Code中可以在配置中"editor.fontLigatures": true, 这样设置之后, 如果在VS Code中连着打出>和=, 其实就会显示成≥
但这是编辑器自己处理的连字效果, 有没有办法强行使一些本来没有连字效果的字符组合产生连字效果, 或者强行使一些有连字效果的字符组合取消连字效果呢? 答案是肯定的. Unicode的Cf字符中, 有以下两个字符.
- 零宽度连字符(zero-width joiner, zwj)U+200D: 用于阿拉伯文等文字中,使不会发生连字的字符间产生连字效果
- 零宽度断字符(zero-width non-joiner, zwnj)U+200C: 用于阿拉伯文、德文等文字中,阻止会发生连字的字符间的连字效果
zwnj的例子大多都和语言相关, 阿拉伯语、德语一类的, 示例也很复杂.
但是zwj就很特殊, 除了阿拉伯语这种特殊语言, 还记得我们文章的开头说了什么吗? 没错, 就是 Emoji!
zwj对Emoji也有效, 本来Emoji就是个设计简单表达心情的表情符号,但随着使用越来越广泛,刮起了一阵“中立表情(Neutral Emojis)”的风,即有男性表情,那就得有对应的女性,有白种人,那就得有黄种人、黑种人,家庭可以是异性恋,那就得有同性恋,有儿子,也得有女儿。如果每种都是单独的字符表示,那Unicode可能也装不下,而且已有的Emoji也不能复用, 因此就想到了用zwj来组合相关Emoji, 形成新的Emoji。
最典型的一个例子:👨👨👦👦这个家庭的Emoji,实际上是由四个Emoji组合而成,表示两个爸爸和两个儿子一家: \uD83D\uDC68\u200D\uD83D\DC68\u200D\D83D\DC66\u200D\D83D\uDC66
每个字符间用特殊字符 \u200D(zero width joiner) 连接起来. 总共占用了22个字节,每个表情成分是四个字节,而每个控制字符只占用两个字节。
四、注意事项
已经说了这么多,相信诸位也已经知道了emoji究竟是什么,回到文章开头前言处,微信为何能显示😤这个表情,也不言自明了。
读到这里,你长输一口气:“终于要结束了!”。抱歉,其实还没完。。。
既然emoji就是一个字符,那么在计算机程序中,对它的操作、存储,也自然是和普通字符没什么差别,本质就是字符的编码问题。那这是不是意味着,在互联网程序中,凡是可以输入字符的地方,其实也就可以输入emoji、乃至所有unicode字符呢? 最差也就是某些古老的客户端没法正确展示嘛!真是如此,还是说服务器端有必要对unicode字符做一些限制呢? 答案是肯定的,在很多情况下,的确要对字符进行限制。这样做的原因有很多,这里列举以下几个原因,进行说明。
4.1 数据库不支持
这主要就是MySQL的坑了,MySQL 5.5.3版本之前,设置的所谓utf-8格式,其实只支持三个字节长度的utf-8,不支持四字节长度。之后的版本才支持四字节长度,而为了兼容以前的版本,指定表结构、字段类型为utf-8,其实还是只支持三字节的utf8mb3,只有显示指定utf8mb4,才是支持四字节的utf-8.
不过这也不能把锅全甩给MySQL,谁让MySQL支持UTF-8太早了呢,根据Wiki[25]所述。
这是由于MySQL在4.1版本开始支持UTF-8编码(当时参考UTF-8草案版本为RFC 2279)时,为2003年,并且在同年9月限制了其实现的UTF-8编码的空间占用最多为3字节,而UTF-8正式形成标准化文档(RFC 3629)是其之后。限制UTF-8编码实现的编码空间占用一般被认为是考虑到数据库文件设计的兼容性和读取最优化,但实际上并没有达到目的,而且在UTF-8编码开始出现需要存入非基本多文种平面的Unicode字符(例如emoji字符)时导致无法存入(由于3字节的实现只能存入基本多文种平面内的字符)。直到2010年在5.5版本推出“utf8mb4”来代替、“utf8”重命名为“utf8mb3”并调整“utf8”为“utf8mb3”的别名,并不建议使用旧“utf8”编码,以此修正遗留问题。
4.2 打印机不支持
也许你的数据库,你的程序都可以正常的存储、展示Unicode字符,但是对那些需要将字符打印出来的场景,还需要考虑打印机等硬件的限制,有些打印机并不具备打印复杂Unicode字符的能力。
4.3 安全原因
安全是个不容忽视的原因,大到苹果、腾讯,也多次在unicode字符上翻车。
列举一下我还记得的一些相关Bug:
- iOS漏洞:发送短信即可令任意苹果手机重启
- iOS 现重大漏洞,神秘字符可让 iPhone 死机!
- 微信「你女朋友撤回了一条消息还亲了你一口」是怎么实现的(微信已经修复了这个bug)?
- “我给男神发了7条隐藏微信消息,结果他向我表白了!”
后面两个微信的bug其实都和我们之前提到的Unicode的“双向控制字符”有关,而又因为方向控制通常用在阿拉伯语中,因此这些漏洞的利用都利用了阿拉伯字符.
苹果的漏洞都没有披露具体细节,原因也只能靠网友自己去猜,蛤乎上偶尔能搜到。这里给出几个链接,感兴趣可以看看. 点我 ,还有我,还有我
五、字体与排版
回到文章开头的另一个问题,“😤这个表情真的是图片吗?”,也许你会回答,当然不是啦,现在知道了,它就是个字符,和汉字一样。一个整数就可以表示了,而图片需要用专门的图片格式,BMP、GIF或者JPG等。那么你有没有想过,你是怎么看到这个表情的呢? 不是图形眼睛怎么能看到呢?
这就要扯到字体上去了,这块不是本文重点,但还是在最后顺带一提。
虽然字符本质上几个字节就编码完成了,可以看作和整数一一对应,但是想要将这个字符渲染出来,就是另一套体系,图形学的体系。换字体强迫症者,也许在网上寻找过各种各样的字体进行尝试,下载一个 .ttf 文件,然后双击安装,就拥有了一种新字体。
将一个二进制代表的字符转化为人眼可见的图形,大概的流程就是这样的。
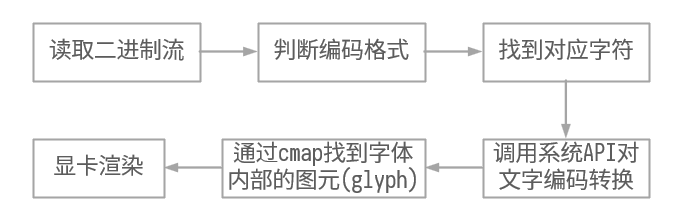
图5.1
不过这块了解不多,也没有查阅太多资料,可能不太准确. 如有错误恳请指出。
参考[33], 可以给出稍微细节点的渲染流程, 如图5.2所示.
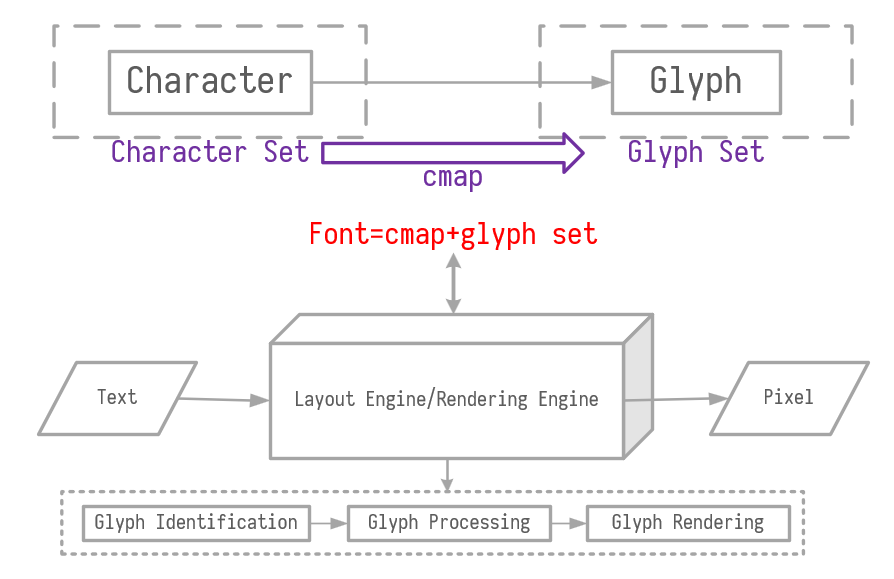
图5.2
还有一点就是: 现有的TTF和OTF格式,单个字体文件都只能支持65535个字符,因此想要用一个字体文件涵盖所有的Unicode字符是不可能的
在计算机的文字处理领域,除了底层的编码、字体,还要考虑对字符如何进行排版,而这又是另一个复杂而又宏大的话题了[33]。就此打住,有机会再研究~
六、Q&A
好了,说了这么多理论,问几个问题,看你是否都能答对。
以下涉及编程语言的部分, Java 版本为 Java 11, Python 版本为 Python 3.8.2, Go 版本为 Go 1.13.8
主要还是以Java为主
6.1 “😤”在不同的编程语言中的length是多少?
通常, 编程语言中 字符串的 length 表示了该字符串的字符数量.
从理论上来说, 长度应该为1, 否则会很麻烦.
就像早期MySQL中认为汉字是2个字符长度, 英文字母是1个字符长度, 那么编程时, 就需要程序员自己计算实际使用的长度, 防止超出varchar(n)的长度范围. 因为不方便, 而且也不符合字符的实际定义, 后续MySQL就改了.
但是各个编程语言又是怎么处理的呢? 是否所有语言所谓的字符就是真正的字符呢?
6.1.1 Java的表现
先来看Java
String s = "😤";
System.out.println(s);
System.out.println(s.length());
System.out.println(s.toCharArray().length);
System.out.println(s.getBytes(StandardCharsets.UTF_8).length);
System.out.println(s.codePointAt(0));
System.out.println(s.codePointAt(1));
2
2
4
128548
56868实际上, Java认为字符串的长度是2.
Java 8之前, Java中的String, 内部存储结构就是char数组, 每个char都是一个UTF-16字符, 所以String的长度就是UTF-16字符的数量.
在Java 9之后, 虽然Java的String内部存储改用了 byte 数组, 但实际目的只是为了减少字符串占用的存储空间, 并不是彻底地改变了Java String中char的定义. 通过String的源码 可以看到当前String中核心的几个属性是:
private final byte[] value;
private final byte coder;
private int hash;
static final boolean COMPACT_STRINGS;如果COMPACT_STRINGS是false, 那么本质上和JDK 8没有区别, 每个char都是一个UTF-16, 占两个字节.
默认COMPACT_STRINGS是true, 此时, String的存储有两种可能的形式, 通过coder区分, coder为0时表示LATIN1, 为1时表示UTF16. LATIN1实际上就是ISO-8859-1字符集, 即如果一个String的只包含了ISO-8859-1字符集的字符, 那么coder=0, 一个字符用一个byte存储即可, 而出现该字符集之外的字符, coder=1, 一个字符用两个byte存储, 即UTF-16的编码方式. 查看String中的coder()和isLatin1()方法, 也可看出是COMPACT_STRINGS和coder共同决定了字符串的编码方式.
byte coder() {
return COMPACT_STRINGS ? coder : UTF16;
}
private boolean isLatin1() {
return COMPACT_STRINGS && coder == LATIN1;
}如果想修改COMPACT_STRINGS的值, 可以指定JVM参数-XX:-CompactStrings
总结一下其实就是, Java中, 如果字符串是isLatin1的, 那么字符串长度就是字节数, 否则, 就是字节数/2, 至于这两个字节是否真的能表示一个字符, Java表示无所谓.
所以这个复杂的组合字符 👨👨👦👦 在Java中的length实际上就是11
可以说, 由于历史原因, Java原生的String在计算长度时, 并不是很好, 甚至可以说有点坑.
6.1.2 Javascript的表现
再看下Javascript
let s = "😤";
console.log(s.length);
console.log(s.codePointAt(0));
console.log(s.codePointAt(1));
2
128548
56868毕竟前面带了Java, 难怪表现基本一致…
6.1.3 Python的表现
那Python 3上表现又是如何呢?
s = "😤"
print(len(s))
print(ord(s[0]))
# print(ord(s[1])) # 会抛异常
1
128548终于有一个表现符合我们预期的编程语言了, 可喜可贺.
如果考虑组合字符呢?
combiningCharacter = "\u0079\u030C"
print(len(combiningCharacter))
combiningCharacters = "👨👨👦👦"
print(len(combiningCharacters))
2
7所以组合字符, 无论是附加组合标记的, 还是用零宽连字符连接的, 还是被认为是单个字符组成的, 统计的长度也是单个字符的数量, 即Code Point的数量
6.1.4 Go的表现
最近风头正盛的Go语言呢?
s := "😤"
fmt.Println(len(s))
fmt.Println(s[0])
for i := 0; i < len(s); i++ {
fmt.Printf("%x ", s[i])
}
fmt.Println()
fmt.Printf("%+q\n", s)
4
240
f0 9f 98 a4
"\U0001f624"不科学呀, 怎么和其他语言都不一样呢?
直接看Go语言的一篇官方博客[31], Strings, bytes, runes and characters in Go
这篇博客阐述了Go中关于String的几个关键点.
- Go中字符串实际上就等价于一个字节流, 访问一个字符串的index位置, 得到的其实就是对应位置的字节.
- Go只存储字节流, 每个字节的值, 可以随便指定, 因此理论上字节流的编码方式可以是任何编码方式. 但是特殊的是字面量(也就是直接在源码中写出来的), 字面量的值转为什么样的字节流, 实际上在书写源码的那一刻就决定了, 源码文件本身是什么编码格式的, 就对应哪种编码的字节流, 由于Go源码只允许UTF-8格式, 实际上Go的字面量对应的字节流就是UTF-8字节流.
- Go没有使用字符/character的概念, 而是使用了rune
博客中也解释了这么设计的原因, 因为 字符(character) 这个概念很难定义, 考虑到组合字符等, 在 计算/Computing 中字符的概念很容易引起歧义(也的确如此, 包括这篇文章写的也没那么严谨), 因此Go中没有使用字符这个概念, 取而代之的是rune, 一个rune实际上就等价于一个Unicode中的Code Point, 同时rune实际上就是int32的别名, 这也不难理解, 用整数表示Code Point正好.
至于如何迭代string中的rune, Go 提供了 for range语法, 博客示例:
const nihongo = "日本語"
for index, runeValue := range nihongo {
fmt.Printf("%#U starts at byte position %d\n", runeValue, index)
}
U+65E5 '日' starts at byte position 0
U+672C '本' starts at byte position 3
U+8A9E '語' starts at byte position 6如果我们用for range来迭代组合字符呢?
const combiningCharacter = "\u0079\u030C"
for index, runeValue := range combiningCharacter {
fmt.Printf("%#U starts at byte position %d\n", runeValue, index)
}
const combiningCharacters = "😤👨👨👦👦"
for index, runeValue := range combiningCharacters {
fmt.Printf("%#U starts at byte position %d\n", runeValue, index)
}
U+0079 'y' starts at byte position 0
U+030C '̌' starts at byte position 1
U+1F624 '😤' starts at byte position 0
U+1F468 '👨' starts at byte position 4
U+200D starts at byte position 8
U+1F468 '👨' starts at byte position 11
U+200D starts at byte position 15
U+1F466 '👦' starts at byte position 18
U+200D starts at byte position 22
U+1F466 '👦' starts at byte position 25这是和Python一样的结果.
现在还剩下一个问题, 如果我不仅仅想在for range中访问rune, 有什么办法直接根据索引访问吗?
Go给出的答案是: 语言核心部分不包含该功能, 但是可以使用库. 最常用的就是unicode/utf8了
for i, w := 0, 0; i < len(nihongo); i += w {
runeValue, width := utf8.DecodeRuneInString(nihongo[i:])
fmt.Printf("%#U starts at byte position %d\n", runeValue, i)
w = width
}实际上, 在Unicode的FAQ中[32], 也提到了如何统计string中的字符数量, 点我看看, 其中将统计方法归纳总结成了四类: bytes,Code units,Code points,Grapheme clusters
6.2 字符串反转都如何处理?
如果只是对bytes反转, 是很简单的, 但很多情况下对终端用户来说, 反转之后的字符串还想能够正常显示的, 因此对于复杂文字来说, 需要以字素为单位切分, 而不仅仅是字符/Code point
按照上一个问题的分析, 可以知道Java一般都是按照Code point切分字符的, 但由于用了UTF-16的编码方式, 超过两字节的Code point就会被统计成两个字符, 那么在反转字符串时, 会如何呢?
String s = "😤Ly̌L\uD83D\uDC68\u200D\uD83D\uDC68\u200D\uD83D\uDC66\u200D\uD83D\uDC66Ry̌R😤";
System.out.println(s);
String reverseStr = new StringBuffer(s).reverse().toString();
System.out.println(reverseStr);
😤Ly̌L👨👨👦👦Ry̌R😤
😤ŘyR👦👦👨👨ĽyL😤Emoji还是正常的, 会按照Code point切分, 查看源码可以很清晰的看到对Surrogate做了特殊处理. 但是对组合字符就无能为力了
Python 3应该是一样的表现.
s = "😤Ly̌L👨👨👦👦Ry̌R😤"
print(s)
print(s[::-1])
😤Ly̌L👨👨👦👦Ry̌R😤
😤ŘyR👦👦👨👨ĽyL😤Javascript原生split再反转, 理论上应该是不行的, 测试了一下也的确不行, 使用Array.from可以解决把一个Emoji的Code point当作两个的问题, 但是对组合字符还是无效的.
s = "😤Ly̌L👨👨👦👦Ry̌R😤"
console.log(s)
console.log(s.split("").reverse().join(""))
console.log(Array.from(s).reverse().join(""))
😤Ly̌L👨👨👦👦Ry̌R😤
��ŘyR��������ĽyL��
😤ŘyR👦👦👨👨ĽyL😤Go还是和之前说的一样, string本质上就是字节流, 所以需要封装对字节的处理, 一个示例.
const s = "😤Ly̌L👨👨👦👦Ry̌R😤"
fmt.Println(s)
fmt.Println(Reverse(s))
func Reverse(s string) string {
size := len(s)
buf := make([]byte, size)
for start := 0; start < size; {
r, n := utf8.DecodeRuneInString(s[start:])
start += n
utf8.EncodeRune(buf[size-start:], r)
}
return string(buf)
}
😤Ly̌L👨👨👦👦Ry̌R😤
😤ŘyR👦👦👨👨ĽyL😤其实, 这个问题, 本质上还是在界定字节、Code point、字素的概念, 反转函数究竟是按照byte、Code point还是字素去处理字符串, 可以看到, 语言核心类库一般只支持到按照Code point去切分, 想要处理组合字符等特殊的字素, 需要付出更多的努力
6.3 怎么除去4字节编码的utf-8字符
由于历史因素, 无法修改MySQL的编码, 这时可能就需要在落库时过滤一遍字符串, 将4字节的utf-8字符去除.
对于严格按照Code point切分的语言, 比如python和go, 通过每个字符、rune的长度, 很容易就能判定.
对于Java这种UTF-16存储的, 我们可以利用一个很简单却很容易被忽略的事实: UTF-8编码的3字节的字符范围, 就是BMP的范围, 也就是说, 基本UTF-16范围的字符, 用UTF-8都不超过3字节, 所以只要判断一个字符是否是Surrogate, 移除所有Surrogate, 其实就可以保证不会超过UTF-8的3字节范围.
public static String removeSurrogate(String originStr) {
StringBuilder returnStr = new StringBuilder();
for (char ch : originStr.toCharArray()) {
if (!Character.isSurrogate(ch)) {
returnStr.append(ch);
}
}
return returnStr.toString();
}Footnote
- 1.Kawasaki, Tamaki. Emoji(表情符号)是如何诞生并在全世界普及的?. 12 Aug. 2018, www.gov-online.go.jp/eng/publicity/book/hlj/html/201808/201808_12_ch.html.↩
- 2.Wikipedians. “World Emoji Day.” Wikipedia, Wikimedia Foundation, 10 Aug. 2020, en.wikipedia.org/wiki/World_Emoji_Day.↩
- 3.池昌海 . “语言学概论.” 浙江大学-远程教育学院, 16 Dec. 2010, 218.108.57.198/yyxgl1/.↩
- 4.李玲璞. "汉字学元点理论及相关问题——兼谈汉字认知的若干误区." 中国文字研究 (2004).↩
- 5.Wikipedians. “Character Encoding.” Wikipedia, Wikimedia Foundation, 25 Aug. 2020, en.wikipedia.org/wiki/Character_encoding.↩
- 6.Tero, Paul. “Unicode, UTF8 & Character Sets: The Ultimate Guide.” Smashing Magazine, 6 June 2012, www.smashingmagazine.com/2012/06/all-about-unicode-utf8-character-sets/.↩
- 7.Wikipedians. “Plane (Unicode).” Wikipedia, Wikimedia Foundation, 28 Aug. 2020, en.wikipedia.org/wiki/Plane_(Unicode).↩
- 8.Unkown. “Unicode Character Table.” ✔️ ❤️ ★ Unicode Character Table, 6 Sept. 2020, unicode-table.com/en/.↩
- 9.timwhitlock. “Unicode Character Inspector.” apps.timwhitlock.info, 6 Sept. 2020, apps.timwhitlock.info/unicode/inspect.↩
- 10.纤夫张 . “其实你并不懂 Unicode.” 知乎专栏, 31 Dec. 2018, zhuanlan.zhihu.com/p/53714077.↩
- 11.Wikipedians. “UTF-8.” Wikipedia, Wikimedia Foundation, 5 Sept. 2020, en.wikipedia.org/wiki/UTF-8.↩
- 12.F. Yergeau. “UTF-8, a Transformation Format of ISO 10646.” IETF Tools, 1 Nov. 2003, tools.ietf.org/html/rfc3629.↩
- 13.Cohen, Danny. “ON HOLY WARS AND A PLEA FOR PEACE.” IETF, 1 Apr. 1980, www.ietf.org/rfc/ien/ien137.txt.↩
- 14.Wikipedians. “字节序.” Wikipedia, Wikimedia Foundation, 18 Aug. 2020, zh.wikipedia.org/wiki/字节序.↩
- 15.Unicode. “Glossary of Unicode Terms.” Glossary, 21 May 2020, unicode.org/glossary/.↩
- 16.Wikipedians. “位元組順序記號.” Wikipedia, Wikimedia Foundation, 30 June 2020, zh.wikipedia.org/wiki/位元組順序記號.↩
- 17.infocodez. “【转载】随便说说字符集和编码.” 博客园, 27 Sept. 2017, www.cnblogs.com/infocodez/p/7600459.html.↩
- 18.Wikipedians. “Unicode控制字符.” Wikipedia, Wikimedia Foundation, 28 July 2020, zh.wikipedia.org/wiki/Unicode控制字符.↩
- 19.Wikipedians. “異體字選擇器.” Wikipedia, Wikimedia Foundation, 4 Sept. 2020, zh.wikipedia.org/wiki/異體字選擇器.↩
- 20.Wikipedians. “組合字符.” Wikipedia, Wikimedia Foundation, 30 May 2019, zh.wikipedia.org/wiki/組合字符.↩
- 21.Zachary. “Emoji与Unicode.” Emoji与Unicode · Zablog, 18 Sept. 2017, zablog.me/2017/09/18/emoji/.↩
- 22.Wikipedians. “Unicode Equivalence.” Wikipedia, Wikimedia Foundation, 7 Aug. 2020, en.wikipedia.org/wiki/Unicode_equivalence.↩
- 23.deerchao. “基本修养:字符集与编码.” 超越代码, 12 Sept. 2019, deerchao.cn/blog/posts/unicode.html.↩
- 24.vstinner. “Programming with Unicode.” 4. Unicode - Programming with Unicode, 23 June 2017, unicodebook.readthedocs.io/unicode.html.↩
- 25.Wikipedians. “UTF-8.” Wikipedia, Wikimedia Foundation, 20 Aug. 2020, zh.wikipedia.org/wiki/UTF-8.↩
- 26.Cenalulu(卢钧轶) . “十分钟搞清字符集和字符编码.” Cenalulu's Tech Blog, 25 Jan. 2015, cenalulu.github.io/linux/character-encoding/.↩
- 27.Wikipedians. “Unicode Font.” Wikipedia, Wikimedia Foundation, 13 July 2020, en.wikipedia.org/wiki/Unicode_font.↩
- 28.DrStrangeLove. “How Are Character Encodings Related to Fonts?” Super User, 15 Nov. 2011, superuser.com/questions/357530/how-are-character-encodings-related-to-fonts.↩
- 29.Belleve. “字符编码与字体的关系是什么?.” 知乎, 27 Apr. 2015, www.zhihu.com/question/29924586.↩
- 30.Davis, Mark, and Christopher Chapman. Unicode Text Segmentation. 19 Feb. 2020, unicode.org/reports/tr29/.↩
- 31.Pike, R. (2013, October 23). Strings, bytes, runes and characters in Go. Retrieved September 19, 2020, from https://blog.golang.org/strings↩
- 32.Unicode Consortium. (2020, September 19). Characters and Combining Marks. Retrieved September 19, 2020, from http://unicode.org/faq/char_combmark.html↩
- 33.Hosken, M., & Gaultney, V. (2003, September 5). Guidelines for Writing System Support: Technical Details: Smart Rendering: Part 1. Retrieved September 20, 2020, from https://scripts.sil.org/cms/scripts/page.php?site_id=nrsi↩
- 34.Unicode Consortium. (2002, October 28). A General Method for Rendering Combining Marks. Retrieved September 20, 2020, from http://www.unicode.org/notes/tn2/↩
 bitcoin
bitcoin